Interactive Exploration of High-dimensional Datasets with PolyPhy and Polyglot
Enhancing Data Interactivty of PolyPhy
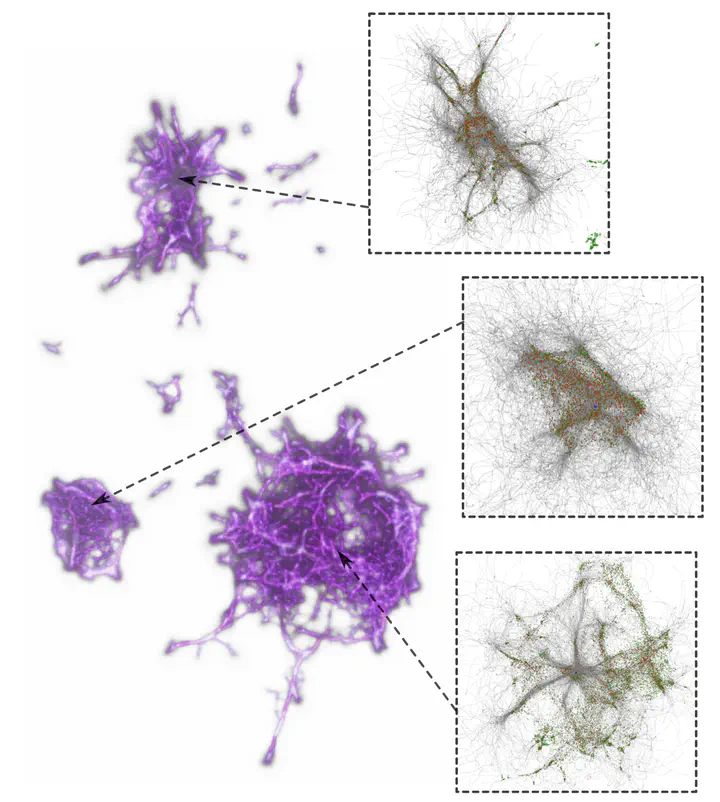
Hello! My name is Kiran and this summer I’ll be working with Polyphy and Polyglot under the mentorship of Oskar Elek. The full proposal is available online.
For a brief overview, the Polyglot app allows users to interact with a 3D network of high-dimensional language embeddings, specfically the Gensim Continuous Skipgram result of Wikipedia Dump of February 2017 (296630 words) dataset. The high-dimensional embeddings are reduced to 3 dimensions using UMAP. The novel MCPM slime mode metric is then used to compute the similarty levels between points (much like how you might compute the Euclidean distance between two points). These similarity levels are used to filter the network and enable users to find interesting patterns in their data they might not find using quantitative methods alone. For example, the network has a distinct branch in which only years are nearby! Users might find other clusters, such as ones with sports words or even software engineering words. Although such exploration may not lead to quantitatively significant conclusions, the ability to explore and test mini hypotheses about the data can lead to important insights that go on to incite quantitatively significant conclusions.
In our project, we aim to expand Polyglot such that any user can upload their own data, once they have computed the MCPM metric using PolyPhy. This will have important applications in building trust in our data and embeddings. This could also help with research on the MCPM metric, which presents a new, more naturalistic way of computing similarity by relying on the principle of least effort. Overall, there is an exciting summer ahead and if you’re interested in keeping up please feel free to check out the Polyglot app on Github!